Integration Into an Existing System
Suppose we have a small daemon that we run on many computers on our network, and it knows many things about them, and does many things. I won't specify exactly what it does or everything it knows because that's irrelevant to the example. However suppose one of the things it knows is the current CPU temperature of the machine it's running on, and we would like access to that data. We heard about this new netidx thing, and we'd like to try it out on this small and not very important case. What code do we need to add to our daemon, and what options do we have for using the data?
We can modify our Cargo.toml to include netidx, and then add a small self contained module, publisher.rs
#![allow(unused)] fn main() { use anyhow::Result; use netidx::{ config::Config, path::Path, publisher::{Publisher, Val, Value}, resolver_client::DesiredAuth, }; pub struct HwPub { publisher: Publisher, cpu_temp: Val, } impl HwPub { pub async fn new(host: &str, current: f64) -> Result<HwPub> { // load the site cluster config from the path in the // environment variable NETIDX_CFG, or from // dirs::config_dir()/netidx/client.json if the environment // variable isn't specified, or from ~/.netidx.json if the // previous file isn't present. Note this uses the cross // platform dirs library, so yes, it does something reasonable // on windows. let cfg = Config::load_default()?; // for this small service we don't need authentication let auth = DesiredAuth::Anonymous; // listen on any unique address matching 192.168.0.0/24. If // our network was large and complex we might need to make // this a passed in configuration option, but lets assume it's // simple. let publisher = Publisher::new(cfg, auth, "192.168.0.0/24".parse()?).await?; // We're publishing stats about hardware here, so lets put it // in /hw/hostname/cpu-temp, that way we keep everything nice // and organized. let path = Path::from(format!("/hw/{}/cpu-temp", host)); let cpu_temp = publisher.publish(path, Value::F64(current))?; // Wait for the publish operation to be sent to the resolver // server. publisher.flushed().await; Ok(HwPub { publisher, cpu_temp }) } pub async fn update(&self, current: f64) { // start a new batch of updates. let mut batch = self.publisher.start_batch(); // queue the current cpu-temp in the batch self.cpu_temp.update(&mut batch, Value::F64(current)); // send the updated value out to subscribers batch.commit(None).await } } }
Now all we would need to do is create a HwPub on startup, and call HwPub::update whenever we learn about a new cpu temperature value. Of course we also need to deploy a resolver server, and distribute a cluster config to each machine that needs one, that will be covered in the administration section.
Using the Data We Just Published
So now that we have our data in netidx, what are our options for consuming it? The first option, and often a very good one for a lot of applications is the shell. The netidx command line tools are designed to make this interaction easy, here's an example of how we might use the data.
#! /bin/bash
netidx subscriber -a anonymous $(netidx resolver -a anonymous list '/hw/*/cpu-temp') | \
while IFS='|' read path typ temp; do
IFS='/' pparts=($path)
if ((temp > 75)); then
echo "host: ${pparts[2]} cpu tmp is too high: ${temp}"
fi
done
Of course we can hook any logic we want into this, the shell is a very powerful tool after all. For example one thing we might want do is modify this script slightly, filter the entries with cpu temps that are too high, and then publish the temperature and the timestamp when it was observed.
#! /bin/bash
netidx subscriber -a anonymous $(netidx resolver -a anonymous list '/hw/*/cpu-temp') | \
while IFS='|' read path typ temp; do
IFS='/' pparts=($path)
if ((temp > 75)); then
echo "/hw/${pparts[2]}/overtemp-ts|string|$(date)"
echo "/hw/${pparts[2]}/overtemp|f64|$temp"
fi
done | \
netidx publisher -a anonymous --bind 192.168.0.0/24
Now we've done something very interesting, we took some data out of
netidx, did a computation on it, and published the result into the
same namespace. We can now subscribe to e.g. /hw/krusty/overtemp-ts
and we will know when that machine last went over temperature. To a
user looking at this namespace in the browser (more on that later)
there is no indication that the over temp data comes from a separate
process, on a separate machine, written by a separate person. It all
just fits together seamlessly as if it was one application.
There is actually a problem here, in that, the above code will not do quite what you might want it to do. Someone might, for example, want to write the following additional script.
#! /bin/bash
netidx subscriber -a anonymous $(netidx resolver -a anonymous list '/hw/*/overtemp-ts') | \
while IFS='|' read path typ temp; do
IFS='/' pparts=($path)
ring-very-loud-alarm ${pparts[2]}
done
To ring a very loud alarm when an over temp event is detected. This would in fact work, it just would not be as timely as the author might expect. The reason is that the subscriber practices linear backoff when it's instructed to subscribe to a path that doesn't exist. This is a good practice, in general it reduces the cost of mistakes on the entire system, but in this case it could result in getting the alarm minutes, hours, or longer after you should. The good news is there is a simple solution, we just need to publish all the paths from the start, but fill them will null until the event actually happens (and change the above code to ignore the null). That way the subscription will be successful right away, and the alarm will sound immediately after the event is detected. So lets change the code ...
#! /bin/bash
declare -A HOSTS
netidx resolver -a anonymous list -w '/hw/*/cpu-temp' | \
sed -u -e 's/^/ADD|/' | \
netidx subscriber -a anonymous | \
while IFS='|' read path typ temp
do
IFS='/' pparts=($path)
temp=$(sed -e 's/\.[0-9]*//' <<< "$temp") # strip the fractional part, if any
host=${pparts[2]}
if ((temp > 75)); then
HOSTS[$host]=$host
echo "/hw/${host}/overtemp-ts|string|$(date)"
echo "/hw/${host}/overtemp|f64|$temp"
elif test -z "${HOSTS[$host]}"; then
HOSTS[$host]=$host
echo "/hw/${host}/overtemp-ts|null"
echo "/hw/${host}/overtemp|null"
fi
done | netidx publisher -a anonymous --bind 192.168.0.0/24
We use resolver list -w to list all paths that match
/hw/*/cpu-temp, and watch for new ones that might appear later. We
take that output, which is just a list of paths, and use sed to
prepend ADD| to it, which makes it a valid subscribe request for
netidx subscriber. We then process the resulting cpu temperature
records. We check for over temp, and we store each host in an
associative array. If this is the first time we've seen a given host,
then we set it's initial overtemp-ts and overtemp to null,
otherwise we don't do anything unless it's actually too hot. Even
though it's only a little longer, this shell program has a number of
advantages over the previous version.
- It will automatically start checking the cpu temp of new hosts as they are added
- It will always publish a row for every host, but will fill it with null if it has never seen that host over temp. This allows clients to subscribe to the overtemp value and receive a timely notification when a host goes over temperature, and it's also nicer to look at in the browser.
- It handles the fractional part of the temperature properly for the shell, which can't do floating point math (in this case we don't care)
Or Maybe Shell is Not Your Jam
It's entirely possible that thinking about the above solution makes you shiver and reinforces for you that nothing should ever be written in shell. In that case it's perfectly possible to do the same thing in rust.
use anyhow::Result; use chrono::prelude::*; use futures::{ channel::mpsc::{channel, Sender}, prelude::*, }; use netidx::{ chars::Chars, config::Config, path::Path, pool::Pooled, publisher::{self, Publisher, Value}, resolver_client::{DesiredAuth, ChangeTracker, Glob, GlobSet}, subscriber::{self, Event, SubId, Subscriber, UpdatesFlags}, }; use std::{ collections::{HashMap, HashSet}, iter, sync::{Arc, Mutex}, time::Duration, }; use tokio::{task, time}; struct Temp { // we need to hang onto this reference to keep the subscription alive _current: subscriber::Dval, timestamp: publisher::Val, temperature: publisher::Val, } async fn watch_hosts( subscriber: Subscriber, publisher: Publisher, tx_current: Sender<Pooled<Vec<(SubId, Event)>>>, temps: Arc<Mutex<HashMap<SubId, Temp>>>, ) -> Result<()> { // we keep track of all the hosts we've already seen, so we don't // publish an overtemp record for any host more than once. let mut all_hosts = HashSet::new(); // we will talk directly to the resolver server cluster. The // ChangeTracker will allow us to efficiently ask if anything new // has been published under the /hw subtree. If anything has, then // we will list everything in that subtree that matches the glob // /hw/*/cpu-temp. let resolver = subscriber.resolver(); let mut ct = ChangeTracker::new(Path::from("/hw")); let pat = GlobSet::new(true, iter::once(Glob::new(Chars::from("/hw/*/cpu-temp"))?))?; loop { if resolver.check_changed(&mut ct).await? { let mut batches = resolver.list_matching(&pat).await?; for mut batch in batches.drain(..) { for path in batch.drain(..) { if let Some(host) = path.split('/').nth(2).map(String::from) { if !all_hosts.contains(&host) { // lock the temps table now to ensure the // main loop can't see an update for an // entry that isn't there yet. let mut temps = temps.lock().unwrap(); // subscribe and register to receive updates let current = subscriber.durable_subscribe(path.clone()); current.updates( UpdatesFlags::BEGIN_WITH_LAST, tx_current.clone(), ); // publish the overtemp records, both with // initial values of Null let timestamp = publisher.publish( Path::from(format!("/hw/{}/overtemp-ts", host)), Value::Null, )?; let temperature = publisher.publish( Path::from(format!("/hw/{}/overtemp", host)), Value::Null, )?; // record that we've seen the host, and // add the published overtemp record to // the temps table. all_hosts.insert(host); temps.insert( current.id(), Temp { _current: current, timestamp, temperature }, ); } } } } } // wait for anything new we've published to be flushed to the // resolver server. publisher.flushed().await; // wait 1 second before polling the resolver server again time::sleep(Duration::from_secs(1)).await } } #[tokio::main] pub async fn main() -> Result<()> { // load the default netidx config let config = Config::load_default()?; let auth = DesiredAuth::Krb5 {upn: None, spn: Some("publish/blackbird.ryu-oh.org@RYU-OH.ORG".into())}; // setup subscriber and publisher let subscriber = Subscriber::new(config.clone(), auth.clone())?; let publisher = Publisher::new(config, auth, "192.168.0.0/24".parse()?).await?; let (tx_current, mut rx_current) = channel(3); // this is where we'll store our published overtemp record for each host let temps: Arc<Mutex<HashMap<SubId, Temp>>> = Arc::new(Mutex::new(HashMap::new())); // start an async task to watch for new hosts publishing cpu-temp records task::spawn(watch_hosts( subscriber.clone(), publisher.clone(), tx_current.clone(), temps.clone(), )); while let Some(mut batch) = rx_current.next().await { let mut updates = publisher.start_batch(); { let temps = temps.lock().unwrap(); for (id, ev) in batch.drain(..) { match ev { Event::Unsubscribed => (), // Subscriber will resubscribe automatically Event::Update(v) => { if let Ok(temp) = v.cast_to::<f64>() { if temp > 75. { let tr = &temps[&id]; tr.timestamp.update(&mut updates, Value::DateTime(Utc::now())); tr.temperature.update(&mut updates, Value::F64(temp)); } } } } } } // release the lock before we do any async operations if updates.len() > 0 { updates.commit(None).await } } Ok(()) }
This does almost exactly the same thing as the shell script, the only semantic difference being that it sends an actual DateTime value for the timestamp instead of a string, which would certainly make life easier for anyone using this data, not to mention it's more efficient.
But I Just Want to Look at My Data
Up to now we've covered using the data in various kinds of programs, but what if you just want to look at it. For that you have two choices, you can write a custom tool that presents your data exactly the way you want, or you can use the netidx browser. A custom tool will always give you more control, but the browser is designed to be pretty flexible, and it allows you to get to an ok looking solution really fast. In the case of the data we've been discussing in this chapter, you get something pretty nice to look at without doing anything at all.
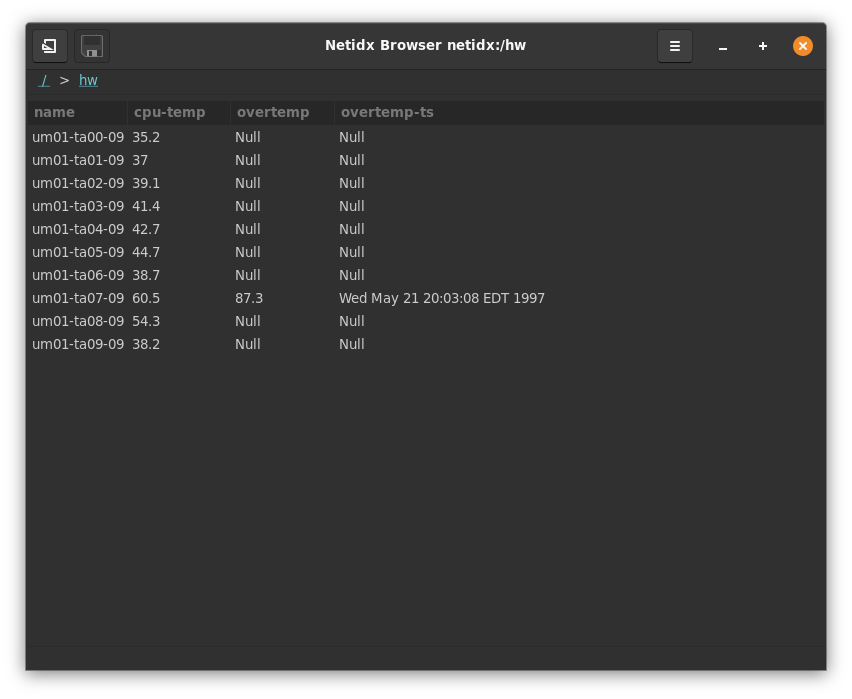
So what's going on here, how did we get a nice looking table out of a tree? When asked to navigate to a path the browser looks for two kinds of regular structures, and will draw something appropriate based on it's findings. One kind is a tree where the 1st level children themselves have a regular set of children. By regular I mean, with the same name. In the example we have
/hw/um01-ta07-09/cpu-temp
/hw/um01-ta07-09/overtemp-ts
/hw/um01-ta07-09/overtemp
But all the 1st level nodes have the same children, so the pattern is,
/hw/${host}/cpu-temp
/hw/${host}/overtemp-ts
/hw/${host}/overtemp
The browser discovers that regularity, and elects to make a row for each $host, and a column for each child of $host. In our case, the data is perfectly regular, and so we end up with a fully populated table with 3 columns, and a row for each host.